



Statistical Model of the English Language
Have you ever wondered how does google predict the next words/terms while you are entering your search terms? You probably have seen this also on your smart phone and wonder how is it done? This is actually part of the field of Natural Language Processing (NLP), a field concerned with interactions between humans and computers.
We used NLP techniques to create an algorithm that predicts possible next words given a sentence, or a term input. To build this algorithm we analyzed millions of sentences from sources such as twitter, news sources, blogs, and others. We kept two parameters in mind when building our app, accuracy and speed. To improve accuracy more data should be analyzed. This also means creating a bigger database which will lead to more processing time, lower execution speeds. Our model achieves good accuracy with good execution speeds. On average it takes ~ 0.006 seconds to make a prediction.
The Data
The data we used to build our model included millions of sentences from different sources. We used a text corpus which contained data from Twitter, news feeds, blogs, books and other sources. To increase the accuracy of our model we used n-grams (n number of words that make a phrase) from different sources. Most statistical models of a language stop at the third or fourth n-gram, at Analytica we added up to 5-grams which we found to improve the accuracy of our model.
The Algorithm
Using the n-grams, we calculated the frequency of each word/phrase in each of the n-grams tables. After that we calculated the Maximum Likelihood Expected (MLE) probability for each word/phrase. Our database contained 5 tables of uni-grams through 5-grams each of which containing frequency and MLE probabilities. All tables were sorted by probability for faster access. We also utilized R libraries to speed up the queries. When a phrase is entered by the user it is first cleaned from numbers, punctuation, etc.
Backoff Model: After that the phrase is compared to the 5-gram language model we have, if no matches are found, we backoff to the 4-gram model and so on. If no matches are found in the n-grams we have, very unlikely, then our algorithm returns the most probable uni-grams.
The figure below shows an example output of our model, you can access and test our App here.
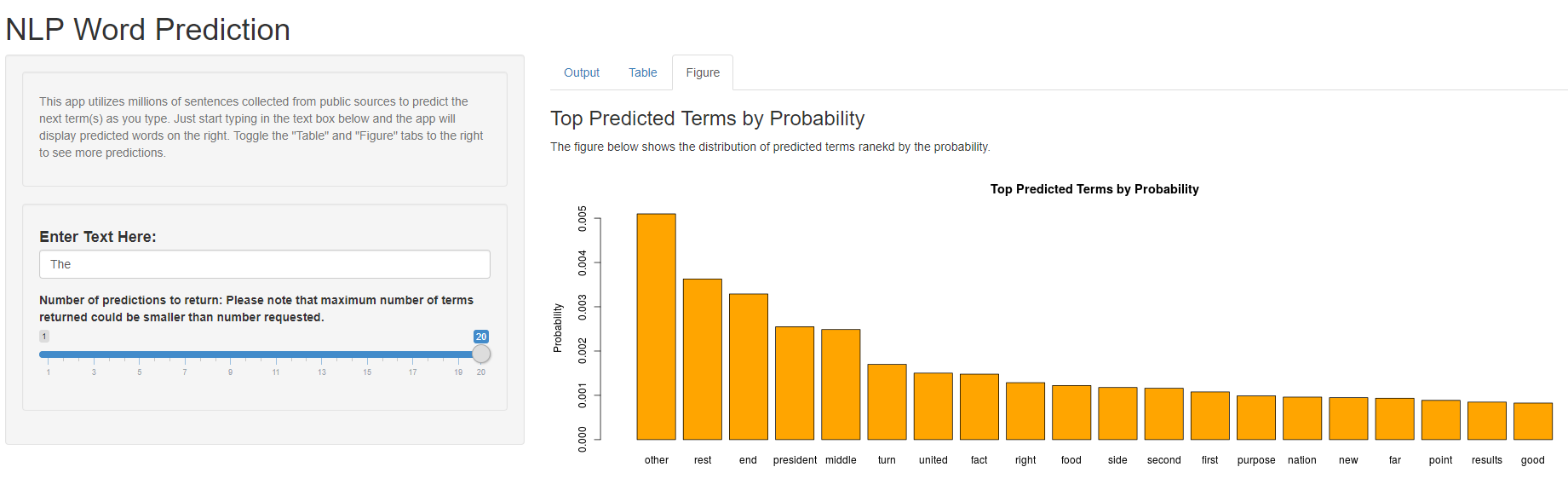
The user can enter the phrase/term in the text box on the left side of the screen. The user can also select the maximum number of predicted terms to return using the slider on the left side of the app. The app will return the phrase with the top predicted term on the right side of the screen. The user can gain more insights on the predicted terms by checking the “Table” and “Figure” tabs on the right hand side of the app.
If you would like to learn more about our work, or if you would like to get our free demo please don’t hesitate to contact us.
[contact-form][contact-field label=’Name’ type=’name’ required=’1’/][contact-field label=’Email’ type=’email’ required=’1’/][contact-field label=’Website’ type=’url’/][contact-field label=’Comment’ type=’textarea’ required=’1’/][/contact-form]